0x80专题
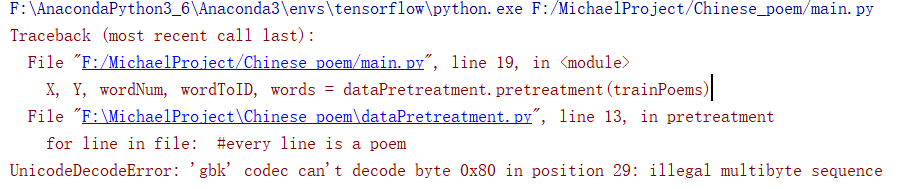
问题 | UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 29解决办法
github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 python读文件: file = open(filename, "r") for line in file: #every line is a poem#print(line)title, poem = line.strip().

python读取文件时提示UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multi
解决办法1. FILE= open('order.log','r', encoding='UTF-8') 解决办法2 FILE= open('order.log','rb')

Linux通过0x80进行系统调用
系统调用:操作系统分为用户态和核心态,当用户调用用户态函数的时候,需要进行用户态到核心态的切换,CPU需要对现场进行保存。如果用户直接调用系统调用,就不需要进行二态切换,提高代码运行效率。并且编译链接后生成的可执行的ELF体积小,运行效率高。用户可以通过系统提供的C语言API进行系统调用,同时也可以通过0x80中断进行调用。下面介绍通过中断进行调用的方法。参数传递:功能号和返回值通过%eax来传递

(20200720已解决)UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0x80 in position 7: invalid start b
问题描述 如题 解决方案 因为pickle文件写入是binary格式,因此读取的时候也需要用binary格式。 return = open("picklefile", 'rb') 出现另外一个问题: _pickle.UnpicklingError: A load persistent id instruction was encountered,but no persistent_load
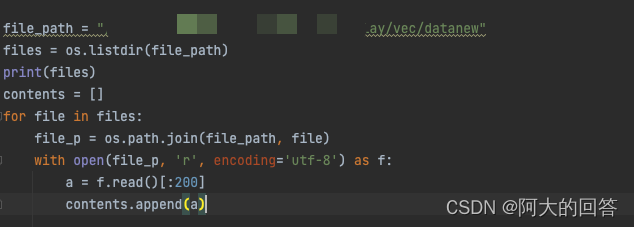
Mac系统解除UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0x80 in position 3131: invalid start byte
file_path = "xxx"files = os.listdir(file_path)contents = []for file in files:file_p = os.path.join(file_path, file)with open(file_p, 'r', encoding='utf-8') as f:a = f.read()[:200]contents.append(a)

UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x80 in...
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x80 in position 25: illegal multibyte sequence 原代码: fp = open('data.txt','r')lines = []for line in fp:line = line.strip()lines.append(line)fp.cl